虛擬主播/虛擬情人 : Open- LLM-VTuber
語音聊天可,可用於Vtuber各種情境,虛擬主播、虛擬情人。。等等
audio in->websocket->ASR->LLM->TTS->websocket->audio out
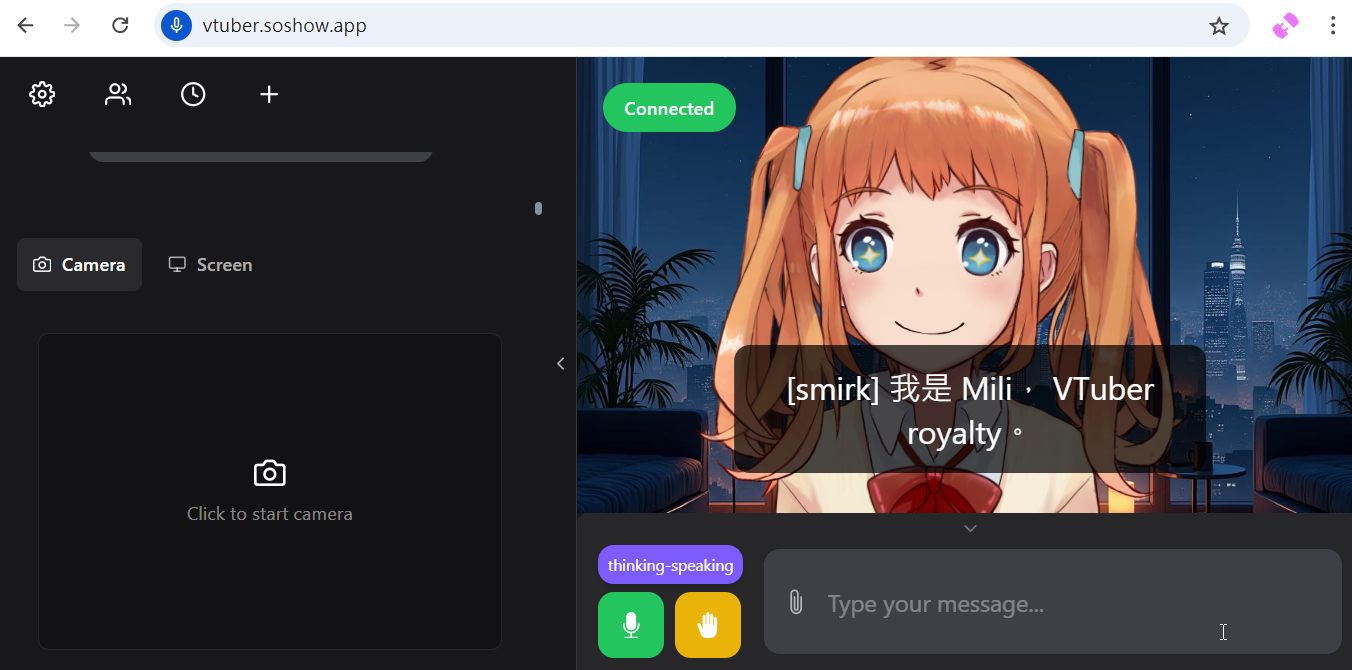
目前版本有多語+翻譯功能,如果只針對特定語言,例如:繁中,則能略過翻譯部分,速度可加快
Live-2D模型部分,有可能搭配其他工具來搭建場景,ex:WEB 3D等,人物照片、表情等 可能搭配 tensorflow.wasm + facemesh.js+ face-landmarks-detection-001.js 等達成realtime 瀏覽器前端 變臉、換背景、特效等
如需參考建置過程 & trouble shooting,可前往我的紀錄
照片生成影片 : Real3DPortrait
只需要一張照片+一段語音,即可生成該語音的影片,中文可,親測可用。範例:
還可搭配動作的影片,生成的影片會模仿該影片中的動作。還能搭配聲音模擬
如需參考建置過程 & trouble shooting,可前往我的紀錄
從影片產生字幕 : OpenAI Whisper
上傳影片或指定youtube影片網址即可自動產生字幕,中文可,同時可擷取聲音檔,親測可用。
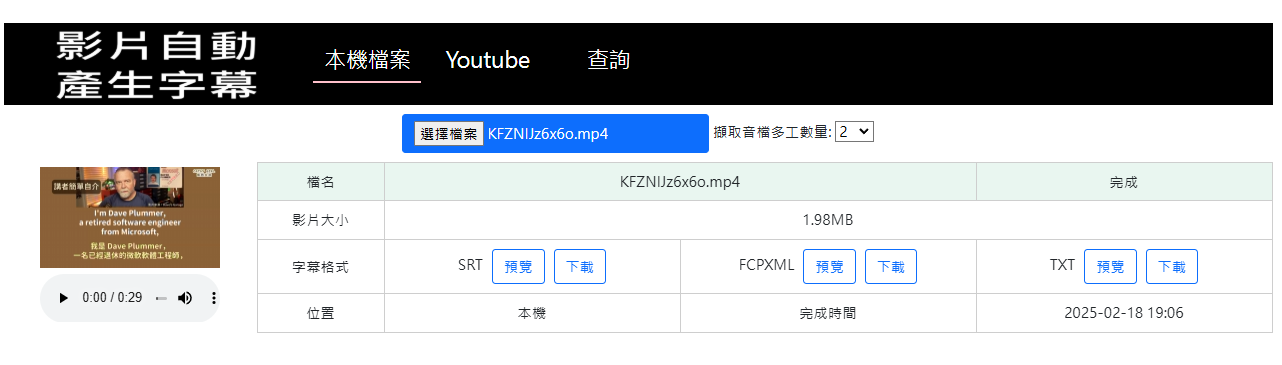
可以產生 vtt srt txt 等格式的字幕,還可生成 macOS專用的 fcpxml格式字幕,youtube 影片可以 batch 批次作業,呼叫 API 傳入多組影片連結,背景陸續依序擷取聲音檔以及產生字幕。
本版突破 wasm程式在瀏覽器處理檔案 2GB大小的限制,最多可處理相當於剩餘可用記憶體大小的檔案,ex:4GB,5GB,6GB以上。
如需參考系統建置及維護,可參考我的紀錄
後續延伸應用: 將字幕依照時間序,直接嵌在影片上, youtuber錄完影片後,可以一鍵生成含有字幕的影片
後續延伸應用: 也可以將生成字幕上傳到 youtube中 成為CC字幕
從照片產生 3D模型 - Microsoft Trellis
拍攝物體不同角度的照片,可產生物體的3D模型,親測可用。
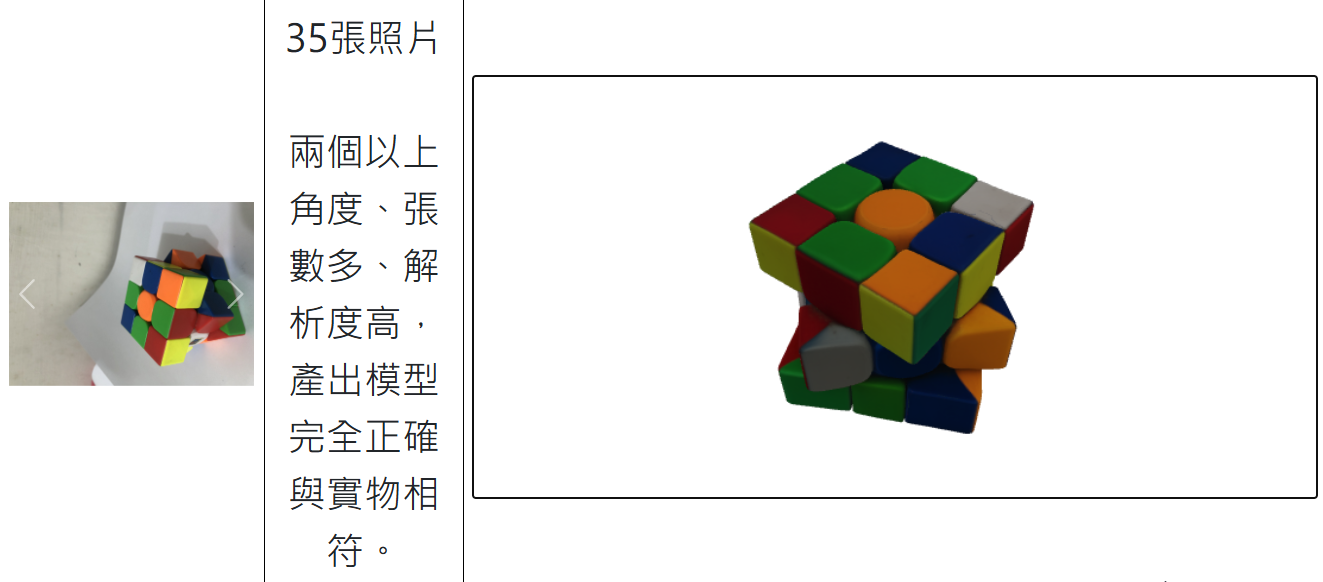
如需參考系統建置及維護,可參考我的紀錄(github)
照片拍攝建議及對比: 前往
因本模型需要較大的 GPU記憶體,如在本機跑這個模型,會滿載並且速度較慢,要測試、線上 DEMO可直接到微軟
後續延伸應用: 產出 3D模型後搭配 browser based 3D viewer (ex:babylon , three.js 等) ,可線上展示供 user操作3D模型,例如:展示商品
後續延伸應用: 3D模型可再加工(切割面、區塊),用於商品生產時,供客戶指定產品某部分 特性用(ex:顏色、材質、規格。。等)
多代理人AI客服 - GraphRAG
用一個模型服務多個專業領域,或是多家公司,依據每家公司提供的資料,AI會優先回應該公司(領域)專屬的內容。
如需參考系統建置及維護,可參考我的紀錄(github)
照片拍攝建議及對比: 前往
因本模型需要較大的 GPU記憶體,如在本機跑這個模型,會滿載並且速度較慢,要測試、線上 DEMO可直接到微軟
後續延伸應用: 產出 3D模型後搭配 browser based 3D viewer (ex:babylon , three.js 等) ,可線上展示供 user操作3D模型,例如:展示商品
後續延伸應用: 3D模型可再加工(切割面、區塊),用於商品生產時,供客戶指定產品某部分 特性用(ex:顏色、材質、規格。。等)